ここで1行目(x1 x2)と1列目(a b c)はラベルに使うものとします。
そこでExcelを開き、保存したいデータをラベルも含めてコピーします。
このときdata1<-excel.ww()と入力し、エンターキーを押しますとデータが読み込まれます。
| 統計ソフトRによる統計処理 |
以下のPDFファイルにRのWindowsにおけるダウンロードの仕方が書かれていますが、バージョンが古いのでご注意を。
ただし大きな流れとしては問題ありません。
Rはhttp://cran.md.tsukuba.ac.jp/において
Windowsをクリック→baseをクリック→Download R 2.10.1 for Windows (32 megabytes)をクリックすればダウンロードできます。
高崎経済大学で日本語版Rの使用できる教室:全てのパソコン室に日本語版がインストールされているわけではないのでご注意ください。
3号館 322,323,325教室
6号館 641,642,643,644教室
7号館 761,762,763,764,765教室
| はじめに |
Rで出てくる
>
は何か入力(命令)を待っている状態である。例えば
>3+2
と入力してEnterキーを押すと,以下の値が出力される。
[1] 5
>は自動的に出力されるので入力する必要はない。
| データのインポート |
インポート(Import)とは、データをRに取り込んでくることです。Rにおけるデータのインポートの仕方はいくつかあります。
Excelにおけるデータをコピーアンドペーストでデータをインポートする方法を説明します。
(これは群馬大学青木先生のサイトにある関数を少し改良させていただきました)
まずRに以下の関数を入力しエンターキーを押します。
| excel.ww<-function(){ data.frame(read.table("clipboard",header=T)) } |
次にインポートしたいデータ(Excelファイル)を準備します。ここをクリック
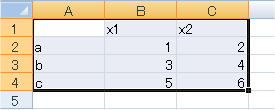
ここで1行目(x1 x2)と1列目(a b c)はラベルに使うものとします。
そこでExcelを開き、保存したいデータをラベルも含めてコピーします。
このときdata1<-excel.ww()と入力し、エンターキーを押しますとデータが読み込まれます。
| > data1<-excel.ww() > data1 x1 x2 a 1 2 b 3 4 c 5 6 |
次にcsvファイルをインポートする方法を紹介します。
最初にcsvファイル(ここではdata02.csvとします)をc:\Program Files\Rに移動させます。
ここで、以下のようにして入力してエンターキーを押せばデータがdata02という変数に読み込まれます。
| data02<-read.csv("c:\\Program Files\\R\\data02.csv",header=T,row.names=1) |
ここでheader=Tとは、列の名前が書いてある1行目のデータは項目として読み取るように指示しています。
またrow.names=1とは、csvファイルの1列目のデータは行の名前を表す項目として読み取るように指示してます。
もし行の名前がない時には、単純にrow.names=1を削除してください。
| 関数のプロット |
例えば自由度8のt分布の確率密度関数をプロットしてみます。自由度mのt分布の確率密度関数はdt(x,m)となります。
| curve(dt(x,8),-4,4) |

上記以外で関数をプロットするには, 下記のようなコマンドを入力する手もあります
|
x <- seq(-4, 4, 0.01) plot(x, dt(x, 8), type="l") |
| データのプロット |
例えば,以下のデータに対する散布図を描きます。これは
| 平均気温 | 平均寿命男 | |
| 北海道 | 8.9 | 78.3 |
| 青森 | 10.1 | 76.27 |
| 宮城 | 12.2 | 78.6 |
| 東京 | 16.2 | 79.36 |
| 新潟 | 13.8 | 78.75 |
| 愛知 | 15.7 | 79.05 |
| 大阪 | 17 | 78.21 |
| 広島 | 16.1 | 79.06 |
| 高知 | 17 | 77.93 |
| 福岡 | 18 | 78.35 |
| 沖縄 | 23.1 | 78.64 |
上で説明したread.csv関数でデータをインポートしたものをdata02と置いた後に, plot(data02)と入力し,エンターキーを押せばokです。
ここでは,散布図の点に名前のラベルをつけてみましょう。これは,以下のように入力します。
| plot(data02,type="n") text(data02,rownames(data02)) |

| 回帰分析 |
まずはコマンドの説明をする。尚データはdata1に入っているとする。
このとき回帰分析は以下のコマンドで行うことができる.
① result1<-lm(従属変数~説明変数1+説明変数2,data=data1)
② result1<-lm(z~x+y, data=data1) # データ系列に名前がついている場合
③ result1<-lm(data[,3]~as.matrix(data[1:2]) #説明変数を行列として扱う
④
x<-data[,1]
y<-data[,2]
z<-data[,3]
result1<-lm(z~x+y)
詳しい解説は以下のpptファイルをご参考に。
| 2群の比較 |
| 因子分析 |
主因子法を用いた因子分析→群馬大学 青木繁伸先生のサイト
| Console(コマンドの入力画面) |
表示される文字を大きくしたい場合:編集(もしくはEdit)→GUI プリファレンスを選択
| データから収益率に変換する |
収益率Rt=(Xt-Xt-1)/Xt-1を計算する場合:
data1<-1:5
exp(diff(log(data1)))-1
[1] 1.0000000 0.5000000 0.3333333 0.2500000
| その他 |
Rにおけるマニュアルはweb上で多数公開されています。詳しくはここをクリックしてください